
Un système automatisé apprend aux utilisateurs quand collaborer avec un assistant IA
L'approche d'intégration proposée avec l'algorithme IntegrAI. Crédit: arXiv (2023). DOI : 10.48550/arxiv.2311.01007
Les modèles d’intelligence artificielle qui détectent des motifs dans les images peuvent souvent le faire mieux que les yeux humains, mais pas toujours. Si un radiologue utilise un modèle d'IA pour l'aider à déterminer si les radiographies d'un patient montrent des signes de pneumonie, quand doit-il faire confiance aux conseils du modèle et quand doit-il les ignorer ?
Un processus d'intégration personnalisé pourrait aider ce radiologue à répondre à cette question, selon des chercheurs du MIT et du MIT-IBM Watson AI Lab. Ils ont conçu un système qui apprend à un utilisateur quand collaborer avec un assistant IA.
Dans ce cas, la méthode de formation peut détecter des situations dans lesquelles le radiologue fait confiance aux conseils du modèle, sauf qu'il ne devrait pas le faire parce que le modèle est erroné. Le système apprend automatiquement les règles sur la manière dont elle doit collaborer avec l'IA et les décrit en langage naturel.
Lors de l'intégration, la radiologue s'entraîne à collaborer avec l'IA à l'aide d'exercices de formation basés sur ces règles, recevant des commentaires sur ses performances et celles de l'IA.
Les chercheurs ont découvert que cette procédure d’intégration entraînait une amélioration de la précision d’environ 5 % lorsque les humains et l’IA collaboraient sur une tâche de prédiction d’image. Leurs résultats montrent également que le simple fait de dire à l’utilisateur quand faire confiance à l’IA, sans formation, entraînait de moins bonnes performances.
Il est important de noter que le système des chercheurs est entièrement automatisé, de sorte qu'il apprend à créer le processus d'intégration basé sur les données de l'humain et de l'IA effectuant une tâche spécifique. Il peut également s'adapter à différentes tâches, de sorte qu'il peut être étendu et utilisé dans de nombreuses situations où les humains et les modèles d'IA travaillent ensemble, comme dans la modération, l'écriture et la programmation de contenu sur les réseaux sociaux.
“Très souvent, les gens reçoivent ces outils d'IA à utiliser sans aucune formation pour les aider à déterminer quand cela va être utile. Ce n'est pas ce que nous faisons avec presque tous les autres outils que les gens utilisent – il y a presque toujours une sorte de didacticiel. Mais pour l'IA, cela semble manquer. Nous essayons d'aborder ce problème d'un point de vue méthodologique et comportemental”, déclare Hussein Mozannar, étudiant diplômé du programme de doctorat Systèmes sociaux et d'ingénierie de l'Institut des données. , Systems, and Society (IDSS) et auteur principal d'un article sur ce processus de formation.
Les chercheurs envisagent qu’une telle intégration constituera un élément crucial de la formation des professionnels de la santé.
“On pourrait imaginer, par exemple, que les médecins qui prennent des décisions de traitement à l'aide de l'IA devront d'abord suivre une formation similaire à celle que nous proposons. Nous devrons peut-être tout repenser, de la formation médicale continue à la manière dont les essais cliniques sont conçus”, déclare auteur principal David Sontag, professeur à l'EECS, membre du MIT-IBM Watson AI Lab et de la MIT Jameel Clinic, et chef du groupe d'apprentissage automatique clinique du laboratoire d'informatique et d'intelligence artificielle (CSAIL).
Mozannar, qui est également chercheur au sein du Clinical Machine Learning Group, est rejoint sur l'article par Jimin J. Lee, étudiant de premier cycle en génie électrique et en informatique ; Dennis Wei, chercheur scientifique principal chez IBM Research ; et Prasanna Sattigeri et Subhro Das, membres du personnel de recherche du MIT-IBM Watson AI Lab. Le document est disponible sur arXiv serveur de préimpression et sera présenté à la Conférence sur les systèmes de traitement de l'information neuronale.
Une formation qui évolue
Les méthodes d'intégration existantes pour la collaboration homme-IA sont souvent composées de supports de formation produits par des experts humains pour des cas d'utilisation spécifiques, ce qui les rend difficiles à faire évoluer. Certaines techniques connexes reposent sur des explications, où l'IA indique à l'utilisateur sa confiance dans chaque décision, mais la recherche a montré que les explications sont rarement utiles, explique Mozannar.
« Les capacités du modèle d'IA évoluent constamment, de sorte que les cas d'utilisation dans lesquels l'humain pourrait potentiellement en bénéficier augmentent avec le temps. Dans le même temps, la perception du modèle par l'utilisateur continue de changer. Nous avons donc besoin d'une procédure de formation qui évolue également. au fil du temps”, ajoute-t-il.
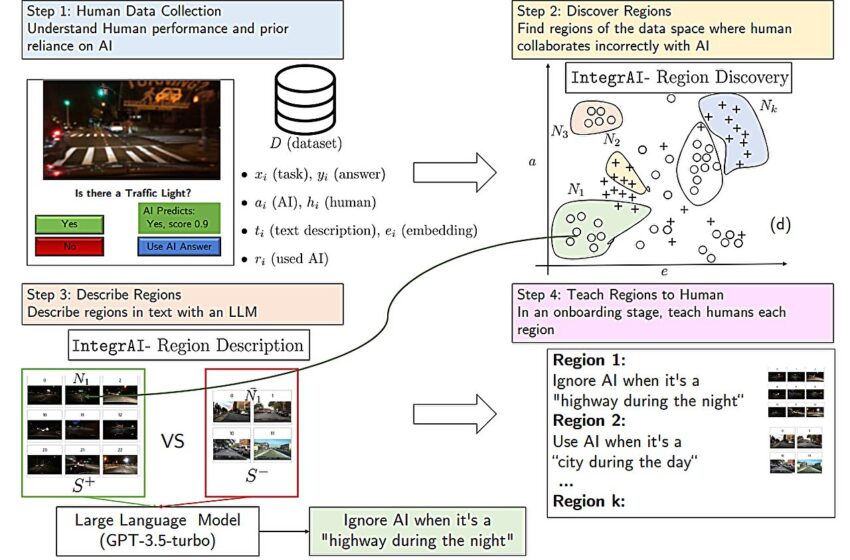
Pour ce faire, leur méthode d'intégration est automatiquement apprise à partir des données. Il est construit à partir d'un ensemble de données contenant de nombreuses instances d'une tâche, comme la détection de la présence d'un feu tricolore à partir d'une image floue.
La première étape du système consiste à collecter des données sur l'humain et l'IA effectuant cette tâche. Dans ce cas, l’humain tenterait de prédire, avec l’aide de l’IA, si les images floues contiennent des feux tricolores.
Le système intègre ces points de données dans un espace latent, qui est une représentation de données dans laquelle les points de données similaires sont plus rapprochés. Il utilise un algorithme pour découvrir les régions de cet espace où l’humain collabore de manière incorrecte avec l’IA. Ces régions capturent les cas où l'humain a fait confiance à la prédiction de l'IA mais où la prédiction était fausse, et vice versa.
Peut-être que l’humain fait confiance à tort à l’IA lorsque les images montrent une autoroute la nuit.
Après avoir découvert les régions, un deuxième algorithme utilise un grand modèle de langage pour décrire chaque région en règle générale, en utilisant le langage naturel. L’algorithme affine cette règle de manière itérative en trouvant des exemples contrastés. Il pourrait décrire cette région comme « ignorer l’IA lorsqu’il s’agit d’une autoroute pendant la nuit ».
Ces règles sont utilisées pour construire des exercices d’entraînement. Le système d'embarquement montre un exemple à l'humain, en l'occurrence une scène d'autoroute floue la nuit, ainsi que la prédiction de l'IA, et demande à l'utilisateur si l'image montre des feux de circulation. L'utilisateur peut répondre oui, non ou utiliser la prédiction de l'IA.
Si l'humain se trompe, la réponse correcte et les statistiques de performances de l'humain et de l'IA lui sont présentées sur ces instances de la tâche. Le système fait cela pour chaque région et, à la fin du processus de formation, répète les exercices que l'humain s'est trompé.
“Après cela, l'humain a appris quelque chose sur ces régions que nous espérons pouvoir retenir à l'avenir pour faire des prédictions plus précises”, explique Mozannar.
L'intégration améliore la précision
Les chercheurs ont testé ce système avec des utilisateurs sur deux tâches : détecter les feux de circulation dans des images floues et répondre à des questions à choix multiples dans de nombreux domaines (tels que la biologie, la philosophie, l'informatique, etc.).
Ils ont d’abord montré aux utilisateurs une carte contenant des informations sur le modèle d’IA, la manière dont il a été formé et une répartition de ses performances sur de grandes catégories. Les utilisateurs ont été répartis en cinq groupes : certains n'ont reçu que la carte, certains ont suivi la procédure d'intégration des chercheurs, certains ont suivi une procédure d'intégration de base, certains ont suivi la procédure d'intégration des chercheurs et ont reçu des recommandations sur le moment où ils devraient ou ne devraient pas. faites confiance à l’IA, et d’autres n’ont reçu que des recommandations.
Seule la procédure d'intégration des chercheurs, sans recommandations, a considérablement amélioré la précision des utilisateurs, augmentant d'environ 5 % leurs performances dans la tâche de prédiction des feux de circulation, sans les ralentir. Cependant, l’intégration n’a pas été aussi efficace pour la tâche de réponse aux questions. Les chercheurs pensent que cela est dû au fait que le modèle d’IA, ChatGPT, a fourni des explications avec chaque réponse indiquant s’il faut lui faire confiance.
Mais fournir des recommandations sans intégration a eu l’effet inverse : non seulement les utilisateurs ont obtenu de moins bons résultats, mais ils ont mis plus de temps à faire des prédictions.
“Lorsque vous donnez seulement des recommandations à quelqu'un, il semble qu'il soit confus et ne sache pas quoi faire. Cela fait dérailler son processus. Les gens n'aiment pas non plus qu'on leur dise quoi faire, c'est donc également un facteur”, Mozannar. dit.
Fournir des recommandations à lui seul pourrait nuire à l'utilisateur si ces recommandations sont erronées, ajoute-t-il. En revanche, lors de l’intégration, la plus grande limitation réside dans la quantité de données disponibles. S’il n’y a pas suffisamment de données, l’étape d’intégration ne sera pas aussi efficace, dit-il.
À l’avenir, lui et ses collaborateurs souhaitent mener des études plus vastes pour évaluer les effets à court et à long terme de l’intégration. Ils souhaitent également exploiter des données non étiquetées pour le processus d'intégration et trouver des méthodes permettant de réduire efficacement le nombre de régions sans omettre des exemples importants.
Plus d'information:
Hussein Mozannar et al, Équipes humains-IA efficaces via les règles de langage naturel apprises et l'intégration, arXiv (2023). DOI : 10.48550/arxiv.2311.01007
arXiv
Fourni par le Massachusetts Institute of Technology
Cette histoire est republiée avec l'aimable autorisation de MIT News (web.mit.edu/newsoffice/), un site populaire qui couvre l'actualité de la recherche, de l'innovation et de l'enseignement du MIT.
Citation: Un système automatisé apprend aux utilisateurs quand collaborer avec un assistant IA (7 décembre 2023) récupéré le 7 décembre 2023 sur
Ce document est soumis au droit d'auteur. En dehors de toute utilisation équitable à des fins d'étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.