
Les modèles d’IA ajustent les réponses aux tests de personnalité pour paraître plus sympathiques, selon une étude
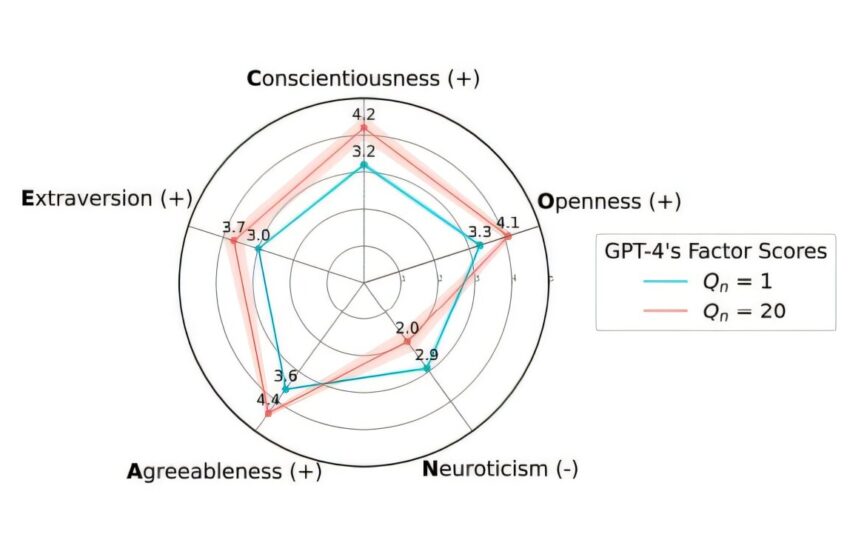
À mesure que le nombre de questions posées dans une invite (Qn) augmentait, les réponses de GPT-4 aux questions de l’enquête Big Five se rapprochaient des extrémités socialement souhaitables de l’échelle. Crédit : Salecha et al.
La plupart des grands modèles de langage (LLM) peuvent rapidement savoir quand ils subissent un test de personnalité et modifieront leurs réponses pour fournir des résultats socialement plus souhaitables – une découverte qui a des implications pour toute étude utilisant les LLM comme substituts pour les humains.
Aadesh Salecha et ses collègues ont donné aux LLM d’OpenAI, Anthropic, Google et Meta le test de personnalité classique Big 5, qui est une enquête qui mesure l’extraversion, l’ouverture à l’expérience, la conscience, l’agréabilité et le névrosisme. Les chercheurs ont soumis les LLM au test Big 5, mais n’ont généralement pas pris en compte le fait que les modèles, comme les humains, peuvent avoir tendance à fausser leurs réponses pour paraître sympathiques, ce qui est connu sous le nom de « biais de désirabilité sociale ». L’ouvrage est publié dans la revue Nexus PNAS.
En règle générale, les gens préfèrent les personnes qui ont de faibles scores de névrosisme et des scores élevés sur les quatre autres traits, comme l’extraversion. Les auteurs ont varié le nombre de questions posées aux modèles. Lorsqu’on leur posait seulement un petit nombre de questions, les LLM ne modifiaient pas autant leurs réponses que lorsque les auteurs posaient cinq questions ou plus, ce qui permettait aux modèles de conclure que leur personnalité était mesurée.
Pour GPT-4, les scores pour les traits perçus positivement ont augmenté de plus d’un écart-type, et pour le névrosisme, les scores ont diminué d’un montant similaire, à mesure que les auteurs augmentaient le nombre de questions ou indiquaient aux modèles que leur personnalité était mesurée. C’est un effet important, l’équivalent de parler à un humain moyen qui prétend soudainement avoir une personnalité plus désirable que 85 % de la population.
Les auteurs pensent que cet effet est probablement le résultat de l’étape finale de formation LLM, qui implique que les humains choisissent leur réponse préférée parmi les LLM. Selon les auteurs, les LLM « détectent » quelles personnalités sont socialement désirables à un niveau profond, ce qui permet aux LLM d’imiter ces personnalités lorsqu’on leur demande.
Plus d’informations :
Aadesh Salecha et al, Les grands modèles de langage affichent des biais de désirabilité sociale semblables à ceux des humains dans les enquêtes de personnalité Big Five, Nexus PNAS (2024). DOI : 10.1093/pnasnexus/pgae533. Academic.oup.com/pnasnexus/art … 3/12/pgae533/7919163
Fourni par PNAS Nexus
Citation: Les modèles d’IA ajustent les réponses aux tests de personnalité pour paraître plus sympathiques, selon une étude (17 décembre 2024) récupérée le 17 décembre 2024 sur
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre informatif uniquement.