
Tester les capacités de raisonnement biologique de grands modèles de langage
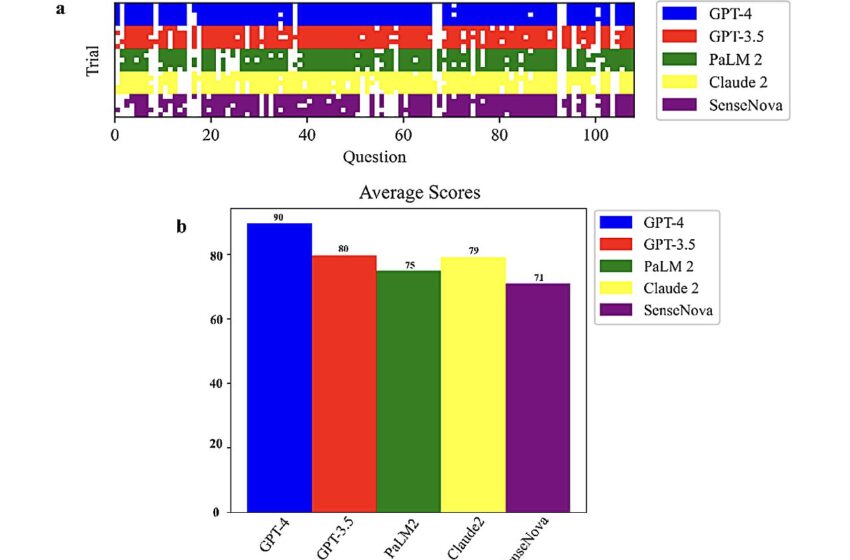
Performance globale de cinq LLM à l'examen biologique. Crédit : Gong et al.
Les grands modèles linguistiques (LLM) sont des algorithmes avancés d'apprentissage en profondeur qui peuvent traiter des invites écrites ou orales et générer des textes en réponse à ces invites. Ces modèles sont récemment devenus de plus en plus populaires et aident désormais de nombreux utilisateurs à créer des résumés de longs documents, à s'inspirer des noms de marques, à trouver des réponses rapides à des requêtes simples et à générer divers autres types de textes.
Des chercheurs de l’Université de Géorgie ont récemment entrepris d’évaluer les connaissances biologiques et les capacités de raisonnement de différents LLM. Leur article, pré-publié sur le arXiv serveur, suggère que le modèle GPT-4 d'OpenAI fonctionne mieux que les autres LLM prédominants sur le marché sur les problèmes de biologie du raisonnement.
“Notre récente publication témoigne de l'impact significatif de l'IA sur la recherche biologique”, a déclaré Zhengliang Liu, co-auteur du récent article, à Tech Xplore. « Cette étude est née de l'adoption et de l'évolution rapides des LLM, notamment suite à l'introduction notable de ChatGPT en novembre 2022. Ces avancées, perçues comme des étapes critiques vers l'intelligence générale artificielle (AGI), ont marqué un passage des approches biotechnologiques traditionnelles à une Méthodologie axée sur l'IA dans le domaine de la biologie.
Dans leur étude récente, Liu et ses collègues ont cherché à mieux comprendre la valeur potentielle des LLM en tant qu'outils pour mener des recherches en biologie. Alors que de nombreuses études antérieures ont souligné l’utilité de ces modèles dans un large éventail de domaines, leur capacité à raisonner sur des données et des concepts biologiques n’a pas encore été évaluée en profondeur.
“Les principaux objectifs de cet article étaient d'évaluer et de comparer les capacités des principaux LLM, tels que GPT-4, GPT-3.5, PaLM2, Claude2 et SenseNova, dans leur capacité à comprendre et à raisonner à travers des questions liées à la biologie”, Liu dit. “Cela a été méticuleusement évalué à l'aide d'un examen à choix multiples de 108 questions, couvrant divers domaines tels que la biologie moléculaire, les techniques biologiques, l'ingénierie métabolique et la biologie synthétique.”
Liu et ses collègues prévoyaient de déterminer comment certains des LLM les plus renommés disponibles aujourd'hui traitent et analysent les informations biologiques, tout en évaluant leur capacité à générer des hypothèses biologiques pertinentes et à s'attaquer aux tâches de raisonnement logique liées à la biologie. Les chercheurs ont comparé les performances de cinq LLM différents à l’aide de tests à choix multiples.
“Les tests à choix multiples sont couramment utilisés pour évaluer les LLM, car les résultats des tests peuvent être facilement notés/évalués/comparés”, a expliqué Jason Holmes, co-auteur de l'article. “Pour cette étude, des experts en biologie ont conçu un test à choix multiples de 108 questions avec quelques sous-catégories.”
Holmes et leurs collègues ont posé cinq fois aux LLM chacune des questions du test qu'ils ont compilé. Cependant, chaque fois qu’une question était posée, ils modifiaient la façon dont elle était formulée.
“Le but de poser la même question plusieurs fois pour chaque LLM était de déterminer à la fois la performance moyenne et la variation moyenne des réponses”, a expliqué Holmes. “Nous avons varié la formulation afin de ne pas baser accidentellement nos résultats sur une formulation optimale ou sous-optimale des instructions qui conduisait à un changement de performances. Cette approche nous donne également une idée de la façon dont les performances varieront dans une utilisation réelle, où les utilisateurs je ne poserai pas les questions de la même manière. »
Les tests effectués par Liu, Holmes et leurs collègues ont permis de mieux comprendre l'utilité potentielle de différents LLM pour aider les chercheurs en biologie. Dans l’ensemble, leurs résultats suggèrent que les LLM répondent bien à diverses questions liées à la biologie, tout en reliant avec précision les concepts ancrés dans la biologie moléculaire fondamentale, la biologie moléculaire commune, l’ingénierie métabolique et la biologie synthétique.
“GPT-4 a notamment démontré des performances supérieures parmi les LLM examinés, atteignant un score moyen de 90 à nos tests à choix multiples dans cinq essais utilisant des invites distinctes”, a déclaré Xinyu Gong, co-auteur de l'article.
« Au-delà d'avoir obtenu le score global le plus élevé au test, GPT-4 a également montré une grande cohérence à travers les essais, soulignant sa fiabilité dans le raisonnement biologique par rapport aux modèles homologues. Ces résultats soulignent l'immense capacité de GPT-4 à aider la recherche et l'enseignement en biologie.
L’étude récente de cette équipe de chercheurs pourrait bientôt inspirer des travaux supplémentaires explorant davantage l’utilisabilité des LLM dans le domaine de la biologie. Les résultats recueillis jusqu'à présent suggèrent que les LLM pourraient être des outils utiles à la fois pour la recherche et l'éducation, par exemple en soutenant le tutorat des étudiants en biologie, la création d'outils d'apprentissage interactifs et la création d'hypothèses biologiques testables.
“Essentiellement, notre article représente un effort pionnier dans la fusion des capacités de l'IA avancée, en particulier des LLM, avec le domaine complexe et en évolution rapide de la biologie”, a déclaré Liu. “Cela marque un nouveau chapitre dans la recherche biologique, positionnant l'IA non seulement comme un outil de soutien, mais comme un élément central pour naviguer et déchiffrer le paysage biologique vaste et complexe.”
Les progrès futurs des LLM et leur formation continue sur les données biologiques pourraient ouvrir la voie à d’importantes découvertes scientifiques, tout en permettant également la création d’outils pédagogiques plus avancés. Liu, Holmes, Gong et leurs collègues envisagent désormais de mener d'autres études dans ce domaine.
Dans leurs prochains travaux, ils prévoient d’abord de concevoir des stratégies pour surmonter les exigences informatiques et les problèmes liés à la confidentialité associés à l’utilisation de GPT-4, le LLM qui sous-tend ChatGPT. Cela pourrait être réalisé en développant des LLM open source pour automatiser des tâches telles que l'annotation des gènes et l'appariement phénotype-génotype.
“Nous utiliserons la distillation des connaissances de GPT-4, créant des données de suivi d'instructions pour affiner les modèles locaux tels que les modèles de fondation LLaMA”, a déclaré Zihao Wu, co-auteur du document, à Tech Xplore.
« Cette stratégie exploitera les capacités de GPT-4 tout en répondant aux problèmes de confidentialité et de coûts, rendant les outils avancés plus accessibles à la communauté de la biologie. De plus, grâce aux capacités de vision de GPT-4V, nous étendrons nos recherches aux analyses multimodales, en nous concentrant sur les molécules médicamenteuses naturelles. , tels que des agents anticancéreux ou des adjuvants de vaccins, en particulier ceux dont les voies de biosynthèse sont inconnues. »
“Nous étudierons leurs voies chimiques et biosynthétiques ainsi que leurs applications potentielles. La capacité du GPT-4V à reconnaître les structures moléculaires améliorera notre analyse de données multimodales complexes, faisant ainsi progresser notre compréhension et notre application dans la découverte et le développement de médicaments en biologie synthétique.”
Plus d'information:
Xinyu Gong et al, Évaluation du potentiel des principaux modèles de langage à grande échelle pour raisonner des questions de biologie, arXiv (2023). DOI : 10.48550/arxiv.2311.07582
arXiv
© 2023 Réseau Science X
Citation: Test des capacités de raisonnement biologique des grands modèles de langage (19 décembre 2023) récupéré le 19 décembre 2023 sur
Ce document est soumis au droit d'auteur. En dehors de toute utilisation équitable à des fins d'étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.