
Les chercheurs ont élaboré des dizaines de modèles de prévision du COVID-19 : ont-ils réellement été utiles ?
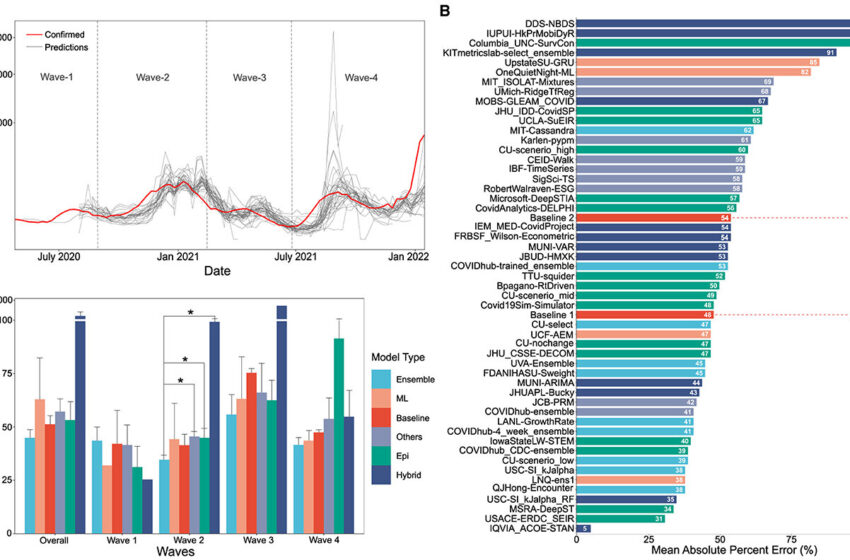
(A) Superposition visuelle des nombres de cas réels et des nombres de cas prévus pour toutes les vagues examinées. Les nombres de cas réels sont indiqués en rouge, les nombres prévus sont indiqués en gris, chaque trace représentant un modèle de prévision COVID-19 différent du CDC sur le graphique sqrt. (B) Valeurs MAPE des modèles de prédiction de cas du CDC américain sur la chronologie complète, c’est-à-dire des vagues I à IV. L’axe des Y est trié de l’erreur décroissante de la plus faible à la plus élevée. Le jeu de couleurs représente la catégorie du modèle. (C) Graphique à barres montrant les résultats du test non paramétrique de Kruskall-Wallis. Un test de Mann-Whitney a également été effectué pour les groupes présentant des différences significatives. L’erreur par catégorie a été obtenue par les modèles à la fois globalement et par vague de la vague 1 à la vague 4. A noter que les modèles hybrides ont un MAPE élevé, c’est-à-dire globalement : 261,16 %, Vague 1 : 25,36 %, Vague 4 : 99,3 %, Vague 3 : 1421,325 %, Vague 4 : 54,74 %). Crédit : Aviral Chharia
Une modélisation précise est essentielle pendant les pandémies pour plusieurs raisons. Les organes politiques doivent prendre des décisions politiques, dont l’adoption peut prendre des semaines et leur mise en œuvre peut prendre encore plus de temps. De même, les organismes de santé publique tels que les hôpitaux, les écoles, les garderies et les centres de santé doivent planifier à l’avance les fortes poussées épidémiques et la distribution des ressources essentielles telles que le personnel, les lits, les respirateurs et l’approvisionnement en oxygène.
Des modèles de prévision précis peuvent aider à prendre des décisions éclairées concernant les précautions nécessaires à des endroits et à des moments spécifiques, à identifier les régions à éviter et à évaluer les risques associés à des activités telles que les rassemblements publics.
Pendant la pandémie de COVID-19, des dizaines de modèles de prévision ont été proposés. Même si leur précision dans le temps et selon le type de modèle reste incertaine, ces modèles ont été utilisés à des degrés divers pour élaborer des politiques.
Les principales questions
Notre étude récente, publiée dans Les frontières de la santé publiquevisait à répondre à plusieurs questions importantes relatives à la modélisation des pandémies.
Premièrement, pouvons-nous établir une mesure standardisée pour évaluer les modèles de prévision de la pandémie ? Deuxièmement, quels ont été les modèles les plus performants au cours des quatre vagues de COVID-19 aux États-Unis, et comment se sont-ils comportés sur l’ensemble de la période ? Troisièmement, existe-t-il des catégories ou des types spécifiques de modèles qui surpassent considérablement les autres ? Quatrièmement, comment se comportent les prévisions des modèles avec des horizons de prévision plus longs ? Enfin, comment ces modèles se comparent-ils à deux bases de référence simples ?
Ne convient pas à l’élaboration des politiques
Les principaux résultats de l’étude montrent que plus des deux tiers des modèles ne parviennent pas à surpasser une simple base de référence statique, et qu’un tiers ne parviennent pas à surpasser une simple prévision de tendance linéaire.
Pour analyser les modèles, nous les avons d’abord classés en approches épidémiologiques, d’apprentissage automatique, d’ensemble, hybrides et autres. Ensuite, nous avons comparé les estimations faites par les modèles aux nombres de cas déclarés par le gouvernement et entre eux, ainsi qu’à deux niveaux de référence dans lesquels le nombre de cas reste statique ou suit une tendance linéaire simple.
Cette comparaison a été réalisée vague par vague et sur l’ensemble de la chronologie de la pandémie, révélant qu’aucune approche de modélisation n’était systématiquement plus performante ou supérieure aux autres, et que les erreurs de modélisation augmentaient au fil du temps.

Valeurs MAPE des modèles de prévision des CDC américains des vagues I à IV. Les modèles sont triés par ordre décroissant de MAPE. Le jeu de couleurs représente la catégorie de modèle. Ici, les « lignes de base » sont représentées en rouge. Crédit : Aviral Chharia
Qu’est-ce qui s’est mal passé et comment y remédier ?
Qu’est-ce qui n’a pas fonctionné et comment combler cette lacune ? Il est essentiel d’améliorer la collecte de données, car la précision de la modélisation dépend de la disponibilité des données, en particulier lors des premières épidémies. Actuellement, les modèles s’appuient sur des données de cas provenant de divers systèmes de déclaration qui varient selon les comtés et souffrent de retards régionaux et temporels. Certains comtés, par exemple, peuvent collecter des données sur plusieurs jours et les rendre publiques en une seule fois, donnant l’impression d’une explosion soudaine de cas. Le manque de données peut limiter la précision de la modélisation dans les comtés dont les programmes de dépistage sont moins robustes.
De plus, ces méthodes ne sont pas uniformes entre les groupes de collecte de données, ce qui entraîne des erreurs imprévisibles. La normalisation des formats de données pourrait simplifier la collecte de données et réduire les erreurs imprévisibles.
Les biais sous-jacents dans les données, comme la sous-déclaration, peuvent produire des erreurs prévisibles dans la qualité des modèles, ce qui nécessite d’ajuster les modèles pour prédire les futures déclarations erronées plutôt que le nombre réel de cas. Par exemple, la disponibilité de kits de test rapide à domicile a conduit de nombreuses personnes à ne pas signaler les résultats des tests aux bases de données gouvernementales. Les données sérologiques et la surmortalité ont permis d’identifier cette sous-déclaration.
Regarder vers l’avant
Même si d’énormes progrès ont été réalisés, les modèles doivent encore être améliorés sur plusieurs fronts, en formulant des hypothèses plus réalistes sur l’effet de la propagation de multiples variants sur le nombre de cas, l’immunité renforcée par les programmes de vaccination, l’impact des confinements, la présence de nombreux variants du virus, l’augmentation de la vaccination, le nombre de doses administrées à un patient, les différents taux de vaccination dans différents comtés et les différents mandats de confinement.
Tous ces facteurs influent sur le nombre de cas, ce qui complique la tâche de prévision. Même dans le cas des modèles d’ensemble, l’étude a montré que ceux-ci ajoutaient des erreurs individuelles au modèle et ne présentaient donc aucune différence significative en termes de performances.
L’erreur de prévision du modèle dans la base de données du CDC américain a augmenté chaque semaine à partir du moment de la prévision. En d’autres termes, la précision des prévisions a diminué à mesure que celles-ci étaient faites à l’avance. Une semaine après la prévision, les erreurs de prévision de la plupart des modèles se sont regroupées juste en dessous de 25 %, mais ont augmenté jusqu’à environ 50 % dans les prévisions à quatre semaines.
Cela suggère que les modèles actuels ne laissent peut-être pas suffisamment de temps aux entités de santé et aux gouvernements pour mettre en œuvre des politiques efficaces.

Les prévisions sont plus précises lorsqu’elles sont proches du moment de la prévision. Le MAPE dans les prévisions de tous les modèles pour différents horizons de prévision est indiqué. Les points dans chaque boîte à moustaches représentent le MAPE sur toutes les prévisions d’un certain modèle pour l’horizon de prévision correspondant. L’axe des Y est le MAE entre le nombre de cas prédit et le nombre de cas signalés. L’axe des X est l’horizon de prévision. Crédit : Aviral Chharia
La modélisation prédictive précise reste essentielle pour lutter contre les futures pandémies. Cependant, l’étude soulève des inquiétudes lorsqu’une politique est formulée directement sur la base de ces modèles. Les modèles comportant des erreurs de prédiction élevées pourraient conduire à une distribution hétérogène des ressources telles que les masques et les respirateurs, ce qui pourrait entraîner un risque de mortalité inutile.
De plus, l’hébergement de ces modèles sur les plateformes publiques officielles des organismes de santé (y compris le CDC américain) risque de leur donner un imprimatur officiel. L’étude suggère que le développement de modèles de prévision de pandémie plus sophistiqués devrait être une priorité.
Cet article fait partie de Science X Dialog, où les chercheurs peuvent présenter les résultats de leurs articles de recherche publiés. Visitez cette page pour obtenir des informations sur Science X Dialog et sur la manière de participer.
Plus d’information:
Aviral Chharia et al, Précision des modèles de prévision COVID-19 des CDC américains, Les frontières de la santé publique (2024). DOI: 10.3389/fpubh.2024.1359368
Aviral Chharia est étudiant diplômé à l’Université Carnegie Mellon. Il a reçu la bourse d’études supérieures ATK-Nick G. Vlahakis à la CMU, la bourse d’excellence en recherche de premier cycle (SURGE) à l’IIT Kanpur, en Inde, et la bourse de recherche MITACS Globalink à l’Université de Colombie-Britannique. De plus, il a reçu deux fois la bourse Dean’s List au cours de ses études de premier cycle. Ses domaines de recherche comprennent la détection humaine, la vision par ordinateur, l’apprentissage profond et l’informatique biomédicale.
Christin Glorioso, MD PhD, est biologiste computationnelle, médecin et entrepreneure en série. Elle est la cofondatrice et PDG d’Academics for the Future of Science, une organisation à but non lucratif de défense et de recherche scientifique et la société mère de Global Health Research Collective. Elle a obtenu son doctorat en neurosciences et son doctorat en médecine à la Carnegie Mellon University-University of Pittsburgh School of Medicine et a été chercheuse postdoctorale au MIT.
Citation:Les chercheurs ont élaboré des dizaines de modèles de prévision de la COVID-19. Ont-ils réellement été utiles ? (2024, 8 juillet) récupéré le 8 juillet 2024 à partir de
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre d’information uniquement.