
Les chatbots IA sont-ils adaptés aux hôpitaux ? Les capacités de diagnostic des grands modèles linguistiques testées
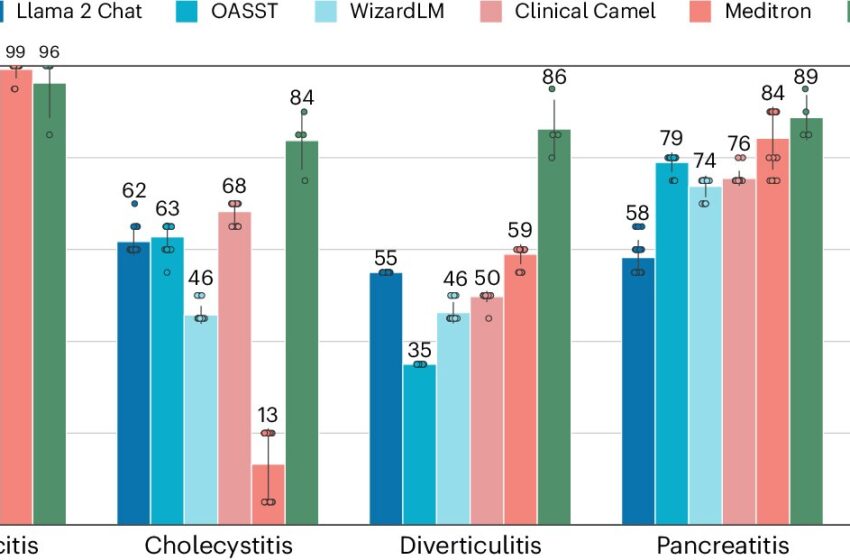
Les LLM posent des diagnostics bien pires que les médecins lorsqu’ils disposent de toutes les informations. Crédit : Médecine naturelle (2024). DOI : 10.1038/s41591-024-03097-1
Les modèles de langage de grande taille peuvent réussir les examens médicaux avec brio, mais les utiliser pour établir des diagnostics serait actuellement une grave négligence. Les chatbots médicaux établissent des diagnostics hâtifs, ne respectent pas les directives et mettraient la vie des patients en danger.
C’est la conclusion à laquelle est parvenue une équipe de la TUM. Pour la première fois, ils ont étudié de manière systématique si cette forme d’intelligence artificielle (IA) pouvait être adaptée à la pratique clinique quotidienne.
Malgré les lacunes actuelles, les chercheurs voient un potentiel dans cette technologie. Ils ont publié une méthode qui pourrait être utilisée pour tester la fiabilité des futurs chatbots médicaux.
Les grands modèles linguistiques sont des programmes informatiques entraînés avec des volumes de texte considérables. Des variantes spécialement entraînées de la technologie à l’origine de ChatGPT résolvent désormais presque parfaitement les examens finaux des études médicales.
Mais une telle IA serait-elle capable de prendre en charge les tâches des médecins aux urgences ? Pourrait-elle prescrire les examens appropriés, poser le bon diagnostic et créer un plan de traitement en fonction des symptômes du patient ?
Une équipe interdisciplinaire dirigée par Daniel Rückert, professeur d’intelligence artificielle en soins de santé et en médecine à la TUM, a abordé cette question dans un article publié dans la revue Médecine naturelle.
Pour la première fois, des médecins et des experts en IA ont étudié systématiquement le succès de différentes variantes du grand modèle de langage open source Llama 2 dans l’établissement de diagnostics.
Reconstitution du parcours depuis les urgences jusqu’au traitement
Pour tester les capacités de ces algorithmes complexes, les chercheurs ont utilisé des données anonymisées de patients provenant d’une clinique aux États-Unis. Ils ont sélectionné 2 400 cas à partir d’un ensemble de données plus vaste. Tous les patients étaient venus aux urgences avec des douleurs abdominales. Chaque description de cas se terminait par l’un des quatre diagnostics et un plan de traitement. Toutes les données enregistrées pour le diagnostic étaient disponibles pour les cas, depuis les antécédents médicaux et les valeurs sanguines jusqu’aux données d’imagerie.
« Nous avons préparé les données de manière à ce que les algorithmes puissent simuler les procédures et les processus décisionnels réels à l’hôpital », explique Friederike Jungmann, médecin assistante au département de radiologie de la clinique rechts der Isar de la TUM et auteur principal de l’étude avec l’informaticien Paul Hager.
« Le programme ne disposait que des informations dont disposaient les vrais médecins. Par exemple, il devait décider lui-même s’il fallait demander une numération sanguine, puis utiliser ces informations pour prendre la décision suivante, jusqu’à ce qu’il établisse enfin un diagnostic et un plan de traitement. »
L’équipe a constaté qu’aucun des grands modèles linguistiques ne demandait systématiquement tous les examens nécessaires. En fait, les diagnostics des programmes devenaient moins précis à mesure qu’ils disposaient d’informations sur le cas. Souvent, ils ne suivaient pas les directives de traitement, ordonnant parfois des examens qui auraient eu de graves conséquences sur la santé des patients réels.
Comparaison directe avec les médecins
Dans la deuxième partie de l’étude, les chercheurs ont comparé les diagnostics de l’IA pour un sous-ensemble de données avec ceux de quatre médecins. Alors que ces derniers étaient corrects dans 89 % des cas, le meilleur modèle de langage à grande échelle n’atteignait que 73 %. Chaque modèle reconnaissait certaines maladies mieux que d’autres. Dans un cas extrême, un modèle n’a diagnostiqué correctement l’inflammation de la vésicule biliaire que dans 13 % des cas.
Un autre problème qui empêche les programmes d’être utilisés au quotidien est leur manque de robustesse : le diagnostic établi par un modèle linguistique de grande taille dépendait, entre autres, de l’ordre dans lequel il recevait les informations. Des subtilités linguistiques influençaient également le résultat, par exemple si le programme devait fournir un diagnostic principal, un diagnostic primaire ou un diagnostic final. Dans la pratique clinique quotidienne, ces termes sont généralement interchangeables.
ChatGPT non testé
L’équipe n’a pas testé les grands modèles de langage commerciaux d’OpenAI (ChatGPT) et de Google pour deux raisons principales. D’une part, le fournisseur des données hospitalières a interdit le traitement des données avec ces modèles pour des raisons de protection des données. D’autre part, les experts recommandent vivement de n’utiliser que des logiciels open source pour les applications dans le secteur de la santé.
« Seuls les modèles open source permettent aux hôpitaux de disposer de suffisamment de contrôle et de connaissances pour garantir la sécurité des patients. Lorsque nous testons des modèles, il est essentiel de savoir sur quelles données ils ont été formés. Sinon, nous risquons de les tester avec exactement les mêmes questions et réponses que celles sur lesquelles ils ont été formés. Les entreprises gardent bien sûr leurs données de formation très secrètes, ce qui rend difficile toute évaluation équitable », explique Paul Hager.
« De plus, il est dangereux de baser les infrastructures médicales clés sur des services externes qui actualisent et modifient les modèles à leur guise. Dans le pire des cas, un service dont dépendent des centaines de cliniques pourrait être fermé parce qu’il n’est pas rentable. »
Des progrès rapides
Les progrès de cette technologie sont rapides. « Il est tout à fait possible que dans un avenir proche, un modèle linguistique de grande taille soit mieux adapté à l’établissement d’un diagnostic à partir de l’histoire médicale et des résultats d’examens », déclare le professeur Daniel Rückert. « Nous avons donc mis notre environnement de test à la disposition de tous les groupes de recherche qui souhaitent tester de grands modèles linguistiques dans un contexte clinique. »
Rückert voit un potentiel dans cette technologie : « À l’avenir, les grands modèles linguistiques pourraient devenir des outils importants pour les médecins, par exemple pour discuter d’un cas. Cependant, nous devons toujours être conscients des limites et des particularités de cette technologie et en tenir compte lors de la création d’applications », explique l’expert en IA médicale.
Plus d’information:
Paul Hager et al., Évaluation et atténuation des limites des grands modèles linguistiques dans la prise de décision clinique, Médecine naturelle (2024). DOI : 10.1038/s41591-024-03097-1
Fourni par l’Université Technique de Munich
Citation: Les chatbots IA sont-ils adaptés aux hôpitaux ? Les capacités de diagnostic des grands modèles linguistiques testées (2024, 22 juillet) récupéré le 22 juillet 2024 à partir de
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre d’information uniquement.