
Pourquoi la révision des connaissances acquises après la formation peut créer des effets d’entraînement désordonnés
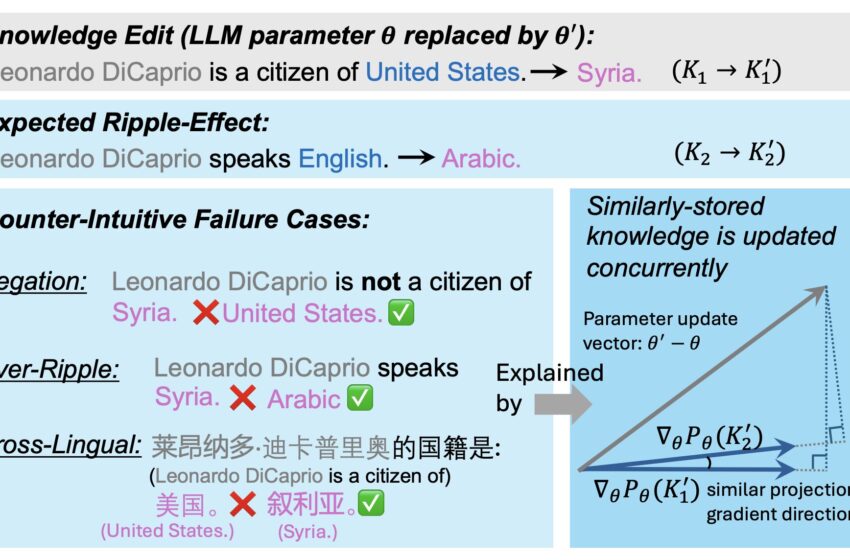
Une illustration des effets d’entraînement dans l’édition des connaissances LLM. Notre travail démontre empiriquement que la corrélation positive entre la similarité des gradients explique une grande partie de l’effet d’entraînement. De plus, des similarités désordonnées entre les points de connaissance créent plusieurs échecs d’effet d’entraînement contre-intuitifs. Crédit : Qin et al.
Depuis l’avènement de ChatGPT, le modèle facilement accessible développé par Open AI, les grands modèles linguistiques (LLM) sont devenus de plus en plus répandus, de nombreux internautes y ayant désormais recours quotidiennement pour obtenir rapidement des réponses à leurs questions, rechercher des informations ou produire des textes personnalisés. Malgré leur capacité remarquable à définir rapidement des mots et à générer des textes écrits pertinents aux questions d’un utilisateur, les réponses fournies par ces modèles ne sont pas toujours précises et fiables.
De plus, les connaissances disponibles dans le monde entier sont en constante évolution. Ainsi, ces modèles peuvent parfois rapporter des informations obsolètes qui leur ont été fournies lors de leur formation, par opposition à d’autres informations pertinentes et à jour diffusées après leur formation. Pour pallier cette limitation des LLM et augmenter la fiabilité de leurs réponses, certains informaticiens explorent la possibilité d’éditer leur base de connaissances après avoir terminé leur formation.
Ces interventions d’édition des connaissances (EC) devraient ensuite influencer l’ensemble du contenu produit par un LLM, créant ainsi un effet d’entraînement. Cela signifie que toutes les réponses futures du modèle sur un sujet donné devraient refléter les nouvelles informations qu’il a acquises sur ce sujet après que ses connaissances ont été modifiées.
Malheureusement, des études suggèrent que ces effets d’entraînement ne se produisent pas toujours. En substance, cela signifie que même si un modèle peut être en mesure de répondre correctement à des questions directes sur des informations modifiées, il peut ne pas intégrer les nouvelles connaissances acquises dans toutes les réponses qu’il génère, y compris celles qui touchent indirectement aux nouvelles informations.
Des chercheurs de l’Université de l’Illinois à Urbana-Champaign ont récemment entrepris de mieux comprendre les processus sous-jacents à la réalisation réussie des effets d’entraînement suite à la modification des connaissances du LLM. Leur article, publié sur le site arXiv Le serveur de préimpression pourrait éclairer les efforts futurs visant à mettre à jour les connaissances sur ces modèles largement utilisés, contribuant ainsi à l’amélioration de ces modèles après la formation.
« De nombreuses recherches antérieures se sont concentrées sur l’édition des connaissances post-formation (EC) pour les modèles de langage (LM) afin de garantir que les connaissances restent exactes et à jour », ont écrit Jiaxin Qin, Zixuan Zhang et leurs collègues dans leur article. « L’une des propriétés souhaitées et la question ouverte de l’EC est de permettre aux LM édités de gérer correctement les effets d’entraînement, où l’on attend du LM qu’il réponde avec précision à ses connaissances logiquement liées. Dans cet article, nous répondons à la question de savoir pourquoi la plupart des méthodes d’EC créent encore des effets d’entraînement désordonnés. »
L’hypothèse clé de cette étude récente est que le stockage des connaissances dans les paramètres d’un LLM influence la mesure dans laquelle les interventions d’EC auront les effets d’entraînement souhaités. Dans leur article, les chercheurs identifient un facteur qui pourrait indiquer la probabilité qu’un fait mis à jour ait des répercussions sur les réponses générées par un LLM après que ses connaissances ont été modifiées.
Ce facteur, que les chercheurs appellent GradSim, correspond essentiellement à la similarité cosinus entre les gradients de connaissances connexes. En effectuant une série de tests, l’équipe a démontré que cet indicateur est fortement corrélé aux effets d’entraînement qui suivent les interventions d’éducation aux connaissances.
« Nous avons mené une analyse approfondie et identifié un indicateur important, GradSim, qui révèle efficacement quand et pourquoi les connaissances mises à jour se répercutent dans les LM », ont écrit les chercheurs. « GradSim est calculé par la similarité cosinus entre les gradients du fait original et ses connaissances associées. Nous observons une forte corrélation positive entre les performances de l’effet d’entraînement et GradSim dans différents LM, méthodes KE et mesures d’évaluation. Des recherches plus poussées sur trois cas d’échec contre-intuitifs (négation, sur-ondulation, multilingue) d’effets d’entraînement démontrent que ces échecs sont souvent associés à un très faible GradSim. »
Cette étude récente menée par Qin, Zhang et leurs collègues met en évidence un facteur crucial qui pourrait aider à prédire dans quelle mesure la révision des connaissances d’un LLM aura des répercussions sur ses réponses futures. Les conclusions de l’équipe pourraient bientôt éclairer de nouveaux efforts visant à mettre à jour efficacement les connaissances des LLM une fois leur formation terminée.
Plus d’information:
Jiaxin Qin et al., Pourquoi les nouvelles connaissances créent-elles des effets d’entraînement désordonnés dans les LLM ?, arXiv (2024). DOI : 10.48550/arxiv.2407.12828
arXiv
© 2024 Réseau Science X
Citation:Pourquoi la révision des connaissances des LLM après la formation peut créer des effets d’entraînement désordonnés (2024, 2 août) récupéré le 2 août 2024 à partir de
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre d’information uniquement.