
Le nouveau modèle peut générer des pistes audio et musicales à partir de diverses entrées de données
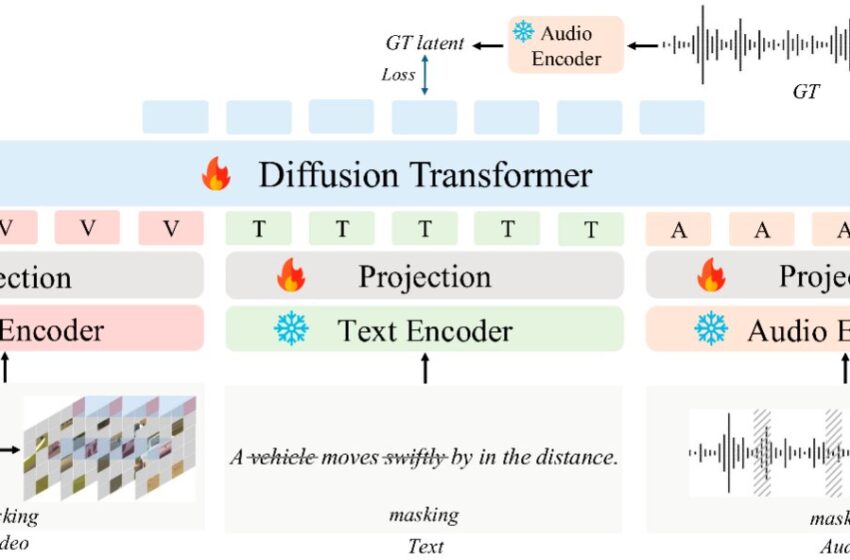
Architecture Audiox. Cette figure décrit l’architecture sous-jacente de l’audio, mettant en évidence son cadre de transformateur de diffusion avec la nouvelle stratégie de masquage multimodal qui permet l’apprentissage de la représentation unifiée à travers les modalités de texte, de vidéo et d’audio. Crédit: Tian et al.
Ces dernières années, les informaticiens ont créé divers outils d’apprentissage automatique très performants pour générer des textes, des images, des vidéos, des chansons et d’autres contenus. La plupart de ces modèles de calcul sont conçus pour créer du contenu en fonction des instructions textuelles fournies par les utilisateurs.
Des chercheurs de l’Université des sciences et de la technologie de Hong Kong ont récemment introduit Audiox, un modèle qui peut générer des pistes audio et musicales de haute qualité en utilisant des textes, des séquences vidéo, des images, de la musique et des enregistrements audio comme entrées. Leur modèle, introduit dans un article publié sur le arxiv Preprint Server, s’appuie sur un transformateur de diffusion, un algorithme avancé d’apprentissage automatique qui exploite l’architecture dite du transformateur pour générer du contenu en déformant progressivement les données d’entrée qu’elle reçoit.
“Nos recherches découlent d’une question fondamentale de l’intelligence artificielle: comment les systèmes intelligents peuvent-ils réaliser une compréhension et une génération trans-modales unifiées?” Wei Xue, l’auteur correspondant du journal, a déclaré à Tech Xplore. “La création humaine est un processus intégré de manière transparente, où les informations de différents canaux sensoriels sont naturellement fusionnées par le cerveau. Les systèmes traditionnels se sont souvent appuyés sur des modèles spécialisés, ne capturent pas et fusionnent ces connexions intrinsèques entre les modalités.”
L’objectif principal de la récente étude dirigée par Wei Xue, Yike Guo et leurs collègues était de développer un cadre d’apprentissage de la représentation unifiée. Ce cadre permettrait à un modèle individuel de traiter les informations sur différentes modalités (c.-à-d. Textes, images, vidéos et pistes audio), au lieu de combiner des modèles distincts qui ne peuvent traiter qu’un type de données spécifique.
“Nous visons à permettre aux systèmes d’IA de former des réseaux conceptuels inter-modaux similaires au cerveau humain”, a déclaré Xue. “Audio, le modèle que nous avons créé, représente un changement de paradigme, visant à relever le double défi de l’alignement conceptuel et temporel. En d’autres termes, il est conçu pour résoudre à la fois les questions« Notre objectif ultime de «l’alignement conceptuel).
Le nouveau modèle basé sur un transformateur de diffusion développé par les chercheurs peut générer des pistes audio ou musicales de haute qualité en utilisant toutes les données d’entrée comme guidage. Cette capacité à convertir “n’importe quoi” en audio ouvre de nouvelles possibilités pour l’industrie du divertissement et les professions créatives. Par exemple, permettant aux utilisateurs de créer de la musique qui correspond à une scène visuelle spécifique ou utilise une combinaison d’entrées (par exemple, textes et vidéos) pour guider la génération de pistes souhaitées.
“Audiox est construit sur une architecture de transformateur de diffusion, mais ce qui le distingue, c’est la stratégie de masquage multimodale”, a expliqué Xue. «Cette stratégie réinvente fondamentalement la façon dont les machines apprennent à comprendre les relations entre les différents types d’informations.
“En obscurcissant les éléments à travers les modalités d’entrée pendant la formation (c’est-à-dire en supprimant sélectivement les correctifs des cadres vidéo, des jetons du texte ou des segments de l’audio) et de la formation du modèle pour récupérer les informations manquantes d’autres modalités, nous créons un espace de représentation unifié.”

Présentation des capacités Audiox. Ce diagramme illustre les capacités polyvalentes d’Audiox sur plusieurs tâches, y compris le texte à audio, la vidéo-audio, la détresse audio, le texte-musique, la vidéo à la musique et la musique. Le modèle démontre de fortes performances dans la génération d’audio contextuellement approprié pour diverses intrants. Crédit: Tian et al.
Audiox est l’un des premiers modèles à combiner des descriptions linguistiques, des scènes visuelles et des modèles audio, capturant la signification sémantique et la structure rythmique de ces données multimodales. Sa conception unique lui permet d’établir des associations entre différents types de données, de manière similaire à la façon dont le cerveau humain intègre les informations ramassées par différents sens (c’est-à-dire la vision, l’audition, le goût, l’odeur et le toucher).
“Audiox est de loin le modèle de fondation le plus complet de tout audio, avec divers avantages clés”, a déclaré Xue. “Premièrement, il s’agit d’un cadre unifié prenant en charge des tâches très diversifiées au sein d’une seule architecture de modèle. Il permet également une intégration intermodale via notre stratégie de formation masquée multimodale, créant un espace de représentation unifié. Il présente des capacités de génération polyvalente, car il peut gérer à la fois un audio général et une musique générale avec une qualité de haute qualité, formé sur des données à grande échelle, y compris nos nouvelles recrues curatives.” “.
Dans les tests initiaux, le nouveau modèle créé par Xue et ses collègues a été trouvé pour produire des pistes audio et musicales de haute qualité, intégrant avec succès des textes, des vidéos, des images et de l’audio. Sa caractéristique la plus remarquable est qu’elle ne combine pas différents modèles, mais utilise plutôt un seul transformateur de diffusion pour traiter et intégrer différents types d’entrées.
“Audiox prend en charge diverses tâches dans une architecture, allant du texte / vidéo à audio à l’intervention audio et à l’achèvement de la musique, progressant au-delà des systèmes qui excellent généralement à des tâches spécifiques”, a déclaré Xue. “Le modèle pourrait avoir diverses applications potentielles, s’étendant sur la production de films, la création de contenu et les jeux.”
. Doi: 10.48550 / arxiv.2503.10522")
Comparaison qualitative entre diverses tâches. Crédit: arxiv (2025). Doi: 10.48550 / arxiv.2503.10522
Audiox pourrait bientôt être amélioré davantage et déployé dans un large éventail de paramètres. Par exemple, cela pourrait aider les professionnels créatifs dans la production de films, d’animations et de contenu pour les médias sociaux.
“Imaginez un cinéaste qui n’a plus besoin d’un artiste Foley pour chaque scène”, a expliqué Xue. “Audiox pourrait générer automatiquement des pas dans la neige, des portes grinçant ou des feuilles bruissantes basées uniquement sur les images visuelles. De même, il pourrait être utilisé par les influenceurs pour ajouter instantanément la musique de fond parfaite à leurs vidéos de danse Tiktok ou par YouTubers pour améliorer leurs vlogs de voyage avec des paysages sons locaux authentiques – tous générés à la demande.”
À l’avenir, Audiox pourrait également être utilisé par les développeurs de jeux vidéo pour créer des jeux immersifs et adaptatifs, dans lesquels l’arrière-plan sonne dynamiquement s’adapter dynamiquement aux actions des joueurs. Par exemple, alors qu’un personnage passe d’un sol en béton à l’herbe, le son de leurs traces pourrait changer, ou la bande sonore du jeu pourrait progressivement devenir plus tendue à l’approche d’une menace ou d’un ennemi.
“Nos prochaines étapes prévues incluent l’extension de l’audio à la génération audio longue”, a ajouté Xue. “De plus, plutôt que d’apprendre simplement les associations à partir de données multimodales, nous espérons intégrer la compréhension esthétique humaine dans un cadre d’apprentissage de renforcement pour mieux s’aligner sur les préférences subjectives.”
Plus d’informations:
Zeyue Tian et al, Audiox: Transformateur de diffusion pour la génération de tout-audio, arxiv (2025). Doi: 10.48550 / arxiv.2503.10522
arxiv
© 2025 Science X Réseau
Citation: Le nouveau modèle peut générer des pistes audio et musicales à partir des diverses entrées de données (2025, 14 avril) récupéré le 15 avril 2025 de
Ce document est soumis au droit d’auteur. Outre toute émission équitable aux fins d’études privées ou de recherche, aucune pièce ne peut être reproduite sans l’autorisation écrite. Le contenu est fourni uniquement à des fins d’information.