
Une course aux armements avec les avancées des grands modèles de langage
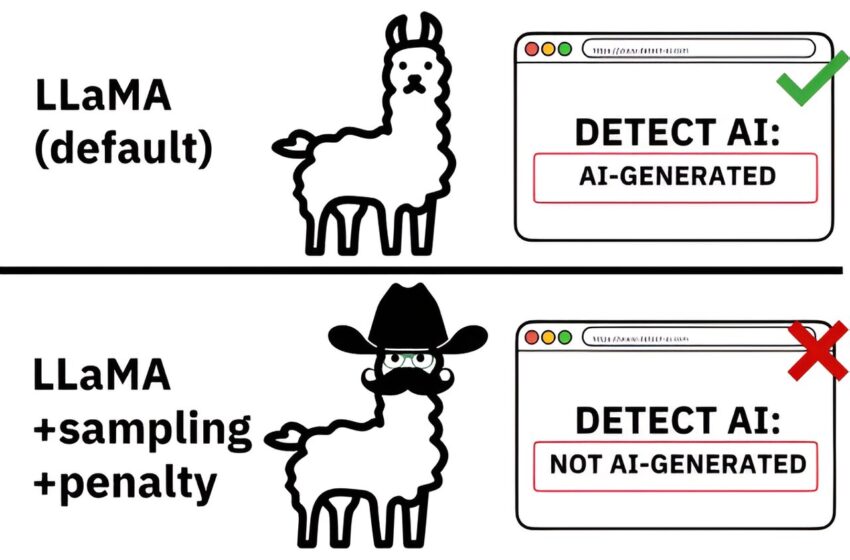
Les détecteurs sont capables de détecter le texte généré par l’IA lorsqu’il ne contient aucune modification ou « déguisement », mais lorsqu’il est manipulé, les détecteurs actuels ne sont pas capables de détecter de manière fiable le texte généré par l’IA. Crédit : arXiv (2024). DOI : 10.48550/arxiv.2405.07940
Depuis quatre ans, les textes générés par des machines trompent les humains. Depuis la sortie de GPT-2 en 2019, les outils de modélisation linguistique à grande échelle (LLM) sont devenus de plus en plus performants dans la création d’histoires, d’articles de presse, de dissertations d’étudiants et bien plus encore, au point que les humains sont souvent incapables de reconnaître lorsqu’ils lisent un texte produit par un algorithme.
Bien que ces LLM soient utilisés pour gagner du temps et même stimuler la créativité dans la conceptualisation et la rédaction, leur pouvoir peut conduire à des abus et à des conséquences néfastes, qui se manifestent déjà dans les espaces où nous consommons de l’information. L’incapacité à détecter le texte généré par une machine ne fait qu’accroître le risque de préjudice.
Les universitaires et les entreprises tentent d’améliorer cette détection en utilisant les machines elles-mêmes. Les modèles d’apprentissage automatique peuvent identifier des modèles subtils de choix de mots et de constructions grammaticales pour reconnaître le texte généré par LLM d’une manière que notre intuition humaine ne peut pas.
Aujourd’hui, de nombreux détecteurs commerciaux prétendent être très efficaces pour détecter le texte généré par machine, avec une précision allant jusqu’à 99 %, mais ces affirmations sont-elles trop belles pour être vraies ? Chris Callison-Burch, professeur en informatique et sciences de l’information, et Liam Dugan, doctorant au sein du groupe de Callison-Burch, ont cherché à le savoir dans leur récent article présenté lors de la 62e réunion annuelle de l’Association for Computational Linguistics. Le travail est publié sur le site arXiv serveur de préimpression.
« À mesure que la technologie de détection des textes générés par machine progresse, la technologie utilisée pour échapper aux détecteurs progresse également », explique Callison-Burch. « C’est une course aux armements, et même si l’objectif de développer des détecteurs robustes est un objectif que nous devons nous efforcer d’atteindre, les détecteurs actuellement disponibles présentent de nombreuses limitations et vulnérabilités. »
Pour étudier ces limitations et proposer une voie à suivre pour le développement de détecteurs robustes, l’équipe de recherche a créé Robust AI Detector (RAID), un ensemble de données de plus de 10 millions de documents comprenant des recettes, des articles de presse, des billets de blog et plus encore, comprenant à la fois du texte généré par l’IA et du texte généré par l’homme.
RAID est le premier référentiel standardisé permettant de tester la capacité de détection des détecteurs actuels et futurs. En plus de créer l’ensemble de données, ils ont créé un classement qui classe publiquement les performances de tous les détecteurs qui ont été évalués à l’aide de RAID de manière impartiale.
« Le concept de classement a été la clé du succès dans de nombreux domaines de l’apprentissage automatique, comme la vision par ordinateur », explique Dugan. « Le benchmark RAID est le premier classement pour la détection fiable de textes générés par l’IA. Nous espérons que notre classement encouragera la transparence et la recherche de haute qualité dans ce domaine en évolution rapide. »
Dugan a déjà constaté l’influence de cet article sur les entreprises qui développent des détecteurs.
« Peu de temps après que notre article soit devenu disponible sous forme de pré-impression et après avoir publié l’ensemble de données RAID, nous avons commencé à voir l’ensemble de données téléchargé plusieurs fois, et nous avons été contactés par Originality.ai, une entreprise de premier plan qui développe des détecteurs de texte généré par l’IA », dit-il.
« Ils ont partagé notre travail dans un article de blog, classé leur détecteur dans notre classement et utilisent RAID pour identifier des vulnérabilités jusqu’alors cachées et améliorer leur outil de détection. C’est inspirant de voir que la communauté apprécie ce travail et s’efforce également de placer la barre plus haut en matière de technologie de détection par IA. »
Alors, les détecteurs actuels sont-ils à la hauteur de la tâche à accomplir ? RAID montre que peu d’entre eux sont aussi performants qu’ils le prétendent.
« Les détecteurs formés sur ChatGPT étaient pour la plupart inutiles pour détecter les sorties de texte générées par machine à partir d’autres LLM tels que Llama et vice versa », explique Callison-Burch.
« Les détecteurs formés sur des articles d’actualité ne sont pas efficaces lorsqu’il s’agit d’examiner des recettes générées par machine ou des textes créatifs. Nous avons découvert qu’il existe une myriade de détecteurs qui ne fonctionnent bien que lorsqu’ils sont appliqués à des cas d’utilisation très spécifiques et lorsqu’ils examinent un texte similaire à celui sur lequel ils ont été formés. »
Les détecteurs défectueux ne posent pas seulement problème parce qu’ils ne fonctionnent pas bien, ils peuvent être aussi dangereux que l’outil d’IA utilisé pour produire le texte en premier lieu.
« Si les universités ou les écoles s’appuyaient sur un détecteur spécialement formé pour détecter l’utilisation de ChatGPT par les étudiants pour rédiger leurs devoirs, elles pourraient accuser à tort les étudiants de tricherie alors qu’ils ne le font pas », explique Callison-Burch. « Elles pourraient également passer à côté d’étudiants qui trichent en utilisant d’autres LLM pour générer leurs devoirs. »
Ce n’est pas seulement la formation d’un détecteur, ou son manque de formation, qui limite sa capacité à détecter un texte généré par une machine. L’équipe a étudié comment des attaques adverses telles que le remplacement de lettres par des symboles similaires peuvent facilement faire dérailler un détecteur et permettre à un texte généré par une machine de passer sous le radar.
« Il s’avère qu’un utilisateur peut effectuer de nombreuses modifications pour échapper à la détection par les détecteurs que nous avons évalués dans cette étude », explique Dugan. « Des choses aussi simples que l’insertion d’espaces supplémentaires, l’échange de lettres contre des symboles ou l’utilisation d’une orthographe alternative ou de synonymes pour quelques mots peuvent rendre un détecteur inutilisable. »
L’étude conclut que, même si les détecteurs actuels ne sont pas encore suffisamment robustes pour être d’une utilité significative dans la société, l’évaluation ouverte des détecteurs sur des ressources vastes, diverses et partagées est essentielle pour accélérer les progrès et la confiance dans la détection, et que la transparence conduira au développement de détecteurs qui résistent dans une variété de cas d’utilisation.
« L’évaluation de la robustesse est particulièrement importante pour la détection, et son importance ne fait que croître à mesure que l’échelle du déploiement public augmente », explique Dugan. « Nous devons également garder à l’esprit que la détection n’est qu’un outil parmi d’autres pour une motivation plus vaste et encore plus précieuse : empêcher les dommages causés par la distribution massive de textes générés par l’IA. »
« Mon travail vise à réduire les préjudices que les LLM peuvent causer par inadvertance et, à tout le moins, à sensibiliser les gens à ces préjudices afin qu’ils puissent être mieux informés lorsqu’ils interagissent avec l’information », poursuit-il. « Dans le domaine de la distribution et de la consommation de l’information, il deviendra de plus en plus important de comprendre où et comment le texte est généré, et cet article n’est qu’un des moyens par lesquels je travaille pour combler ces lacunes dans les communautés scientifiques et publiques. »
Dugan et Callison-Burch ont travaillé avec plusieurs autres chercheurs sur cette étude, notamment les étudiants diplômés de Penn Alyssa Hwang, Josh Magnus Ludan, Andrew Zhu et Hainiu Xu, ainsi qu’une ancienne doctorante de Penn Daphne Ippolito et Filip Trhlik, étudiant de premier cycle à l’University College de Londres. Ils continuent de travailler sur des projets qui visent à améliorer la fiabilité et la sécurité des outils d’IA et la manière dont la société les intègre dans la vie quotidienne.
Plus d’informations :
Liam Dugan et al, RAID : une référence partagée pour une évaluation robuste des détecteurs de texte générés par machine, arXiv (2024). DOI : 10.48550/arxiv.2405.07940
arXiv
Fourni par l’Université de Pennsylvanie
Citation: Détection de texte généré par machine : une course aux armements avec les avancées des grands modèles linguistiques (2024, 13 août) récupéré le 13 août 2024 à partir de
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni à titre d’information uniquement.