
Une approche qui permet aux robots d’apprendre dans des environnements changeants à partir de la rétroaction et de l’exploration humaines
Représentation de l’exploration autonome avec GEAR : la politique alterne entre la tentative d’atteindre un état objectif et le retour à l’état initial. Ce faisant, l’agent reçoit un sous-objectif intermédiaire qui est à la fois proche de l’objectif et atteignable dans le cadre de la politique actuelle. En l’absence de ce paramètre, la stratégie effectue une exploration aléatoire. La politique qui en résulte apprend à faire des allers-retours, tout en explorant efficacement l’espace. Crédit : Balsells et coll.
Pour aider au mieux les humains dans des contextes réels, les robots doivent être capables d’acquérir en permanence de nouvelles compétences utiles dans des environnements dynamiques et en évolution rapide. Cependant, à l’heure actuelle, la plupart des robots ne peuvent effectuer que des tâches pour lesquelles ils ont été préalablement formés et ne peuvent acquérir de nouvelles capacités qu’après une formation complémentaire.
Des chercheurs de l’Université de Washington et du Massachusetts Institute of Technology (MIT) ont récemment introduit une nouvelle approche qui permet aux robots d’acquérir de nouvelles compétences tout en naviguant dans des environnements changeants. Cette approche, présentée lors de la 7e Conférence sur l’apprentissage des robots (CoRL), utilise l’apprentissage par renforcement pour former des robots en utilisant les commentaires humains et les informations recueillies lors de l’exploration de leur environnement.
“L’idée de cet article est venue d’un autre travail que nous avons publié récemment”, a déclaré Max Balsells, co-auteur de l’article, à Tech Xplore. Le document actuel est disponible sur le arXiv serveur de préimpression.
“Dans notre étude précédente, nous avons exploré comment utiliser les commentaires humains collectés (potentiellement inexacts) recueillis auprès de centaines de personnes à travers le monde, pour apprendre à un robot comment effectuer certaines tâches sans s’appuyer sur des informations supplémentaires, comme c’est le cas dans la plupart des cas. travaux antérieurs dans ce domaine.
Alors que dans leur étude précédente, Balsells et leurs collègues avaient obtenu des résultats prometteurs, la méthode qu’ils proposaient devait être constamment réinitialisée pour enseigner de nouvelles compétences aux robots. En d’autres termes, chaque fois que le robot tentait d’accomplir une tâche, son environnement et ses paramètres revenaient à ce qu’ils étaient avant l’essai.
“Devoir réinitialiser la scène est un obstacle si nous voulons que les robots apprennent n’importe quelle tâche avec le moins d’effort humain possible”, a déclaré Balsells. “Dans le cadre de notre récente étude, nous avons donc décidé de résoudre ce problème, en permettant aux robots d’apprendre dans un environnement changeant, toujours uniquement à partir de commentaires humains, ainsi que d’une exploration aléatoire et guidée.”
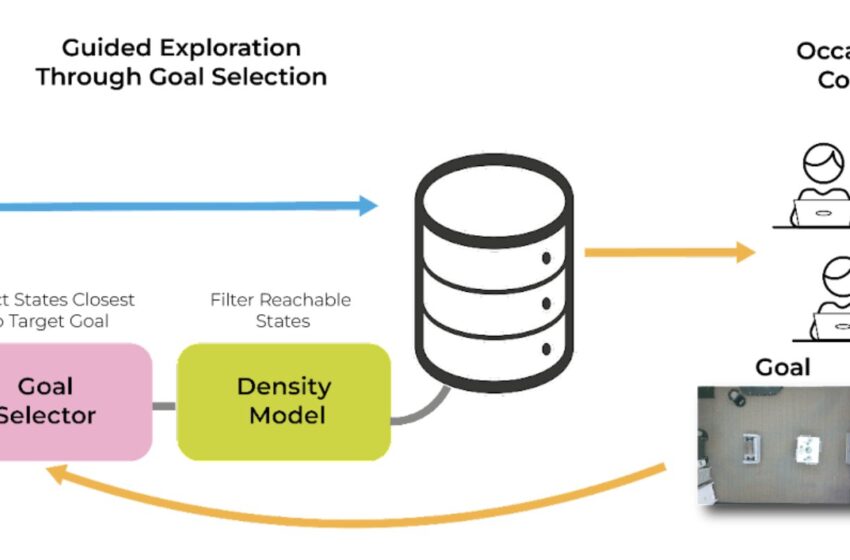
La nouvelle méthode développée par Balsells et ses collègues comporte trois éléments clés, appelés politique, sélecteur d’objectifs et modèle de densité, chacun soutenu par une technique d’apprentissage automatique différente. Le premier modèle tente essentiellement de déterminer ce que le robot doit faire pour se rendre à un endroit spécifique.
“Le but du modèle politique est de comprendre quelles actions le robot doit entreprendre pour arriver à un certain scénario à partir de là où il se trouve actuellement”, a expliqué Marcel Torne, co-auteur de l’article. “Ce premier modèle apprend cela en observant comment l’environnement a changé après que le robot a effectué une action. Par exemple, en regardant où se trouvent le robot ou les objets de la pièce après avoir effectué certaines actions.”
Essentiellement, le premier modèle est conçu pour identifier les actions que le robot devra entreprendre pour atteindre un emplacement ou un objectif cible spécifique. En revanche, le deuxième modèle (c’est-à-dire le sélecteur d’objectif) guide le robot pendant qu’il est encore en train d’apprendre, lui communiquant le moment où il est plus proche d’atteindre un objectif fixé.

Problème de réglage dans GEAR. Le robot explore le monde de manière autonome et sans réinitialisation, en utilisant uniquement des commentaires binaires bon marché et occasionnels d’utilisateurs non experts pour guider l’exploration. Cela permet une mise à l’échelle massive de l’expérience des données et la résolution de tâches beaucoup plus difficiles. Les trois modèles principaux de la méthode sont : la politique utilisée pour contrôler les robots dans le monde réel, le sélecteur d’objectif, qui choisit quel état est le plus proche de l’objectif et le modèle de densité qui filtre les objectifs atteignables par la politique. Crédit : Balsells et coll.
“L’objectif du sélecteur d’objectif est de déterminer dans quels cas le robot était le plus proche d’accomplir la tâche”, a déclaré Balsells. “De cette façon, nous pouvons utiliser ce modèle pour guider le robot en commandant les scénarios qu’il a déjà vus, dans lesquels il était plus proche d’accomplir la tâche. À partir de là, le robot peut simplement effectuer des actions aléatoires pour explorer davantage cette partie de la tâche. ”
L’approche de l’équipe garantit qu’à mesure qu’un robot se déplace dans son environnement, il transmet en permanence les scénarios qu’il rencontre à un site Web spécifique. Les utilisateurs humains participatifs parcourent ensuite ces scénarios et les actions correspondantes du robot, indiquant au modèle quand le robot est plus proche d’atteindre un objectif fixé.
“Enfin, l’objectif du troisième modèle (c’est-à-dire le modèle de densité) est de savoir si le robot sait déjà comment se rendre à un certain scénario à partir de là où il se trouve actuellement”, a déclaré Balsells. “Ce modèle est important pour garantir que le deuxième modèle guide le robot vers des scénarios auxquels le robot peut accéder. Ce modèle est formé sur des données représentant la progression de différents scénarios vers les scénarios dans lesquels le robot s’est retrouvé.”
Le troisième modèle dans le cadre des chercheurs garantit essentiellement que le deuxième modèle guide uniquement le robot vers des endroits accessibles qu’il sait atteindre. Cela favorise l’apprentissage par l’exploration, tout en réduisant les risques d’incidents et d’erreurs.
“Le sélecteur d’objectif guide le robot pour s’assurer qu’il se dirige vers des endroits intéressants”, a expliqué Torne. “En particulier, les modèles de politique et de densité apprennent simplement en observant ce qui se passe autour, c’est-à-dire comment l’emplacement du robot et les objets changent à mesure que le robot interagit. D’un autre côté, le deuxième modèle est formé à l’aide de la rétroaction humaine.”
Notamment, la nouvelle approche proposée par Balsells et ses collègues s’appuie uniquement sur le feedback humain pour guider le robot dans son apprentissage, plutôt que pour démontrer spécifiquement comment effectuer des tâches. Il ne nécessite donc pas de vastes ensembles de données contenant des images de démonstrations et peut promouvoir un apprentissage flexible avec moins d’efforts humains.
“En utilisant le troisième modèle pour savoir à quels scénarios le robot peut réellement accéder, nous n’avons rien à réinitialiser, le robot peut apprendre en continu même si certains objets ne se trouvent plus au même endroit”, a déclaré Torne. “L’aspect le plus important de notre travail est qu’il permet à quiconque d’apprendre à un robot comment résoudre une certaine tâche simplement en le laissant fonctionner tout seul tout en le connectant à Internet, afin que les gens du monde entier le lui disent de temps en temps. à quels moments il était plus proche d’accomplir la tâche.
L’approche introduite par cette équipe de chercheurs pourrait éclairer le développement de cadres davantage basés sur l’apprentissage par renforcement qui permettraient aux robots d’améliorer leurs compétences et d’apprendre dans des environnements dynamiques du monde réel. Balsells, Torne et leurs collègues prévoient désormais d’étendre leur méthode, en fournissant au robot des « primitives » ou des directives de base sur la manière d’exécuter des compétences spécifiques.
“Par exemple, à l’heure actuelle, le robot apprend à chaque fois quels moteurs il doit déplacer, mais nous pourrions programmer la manière dont le robot pourrait se déplacer jusqu’à un certain point d’une pièce, et le robot n’aurait alors pas besoin d’apprendre cela ; il le ferait. j’ai juste besoin de savoir où déménager”, ont ajouté Balsells et Torne.
“Une autre idée que nous souhaitons explorer dans nos prochaines études est l’utilisation de grands modèles pré-entraînés déjà formés pour un ensemble de tâches robotiques (par exemple, ChatGPT pour la robotique), en les adaptant à des tâches spécifiques dans le monde réel à l’aide de notre méthode. Cela pourrait permettre à n’importe qui d’apprendre facilement et rapidement aux robots à acquérir de nouvelles compétences, sans avoir à les recycler à partir de zéro. »
Plus d’information:
Max Balsells et al, Apprentissage par renforcement robotique autonome avec rétroaction humaine asynchrone, arXiv (2023). DOI : 10.48550/arxiv.2310.20608
arXiv
© 2023 Réseau Science X
Citation: Une approche qui permet aux robots d’apprendre dans des environnements changeants à partir de la rétroaction et de l’exploration humaines (28 novembre 2023) récupéré le 28 novembre 2023 sur
Ce document est soumis au droit d’auteur. En dehors de toute utilisation équitable à des fins d’étude ou de recherche privée, aucune partie ne peut être reproduite sans autorisation écrite. Le contenu est fourni seulement pour information.